Unleashing AI Power: Installing and Running LLaMA 3.1 Locally with Ollama

Meta has unveiled significant advancements in natural language processing, introducing upgraded versions of their 8B and 70B models, alongside a new model with 405B parameters. The 405B parameter model notably surpasses GPT-4 across over 150 benchmark datasets. Additionally, the enhanced 8B and 70B models also demonstrate superior performance compared to their respective competitors in various evaluations.
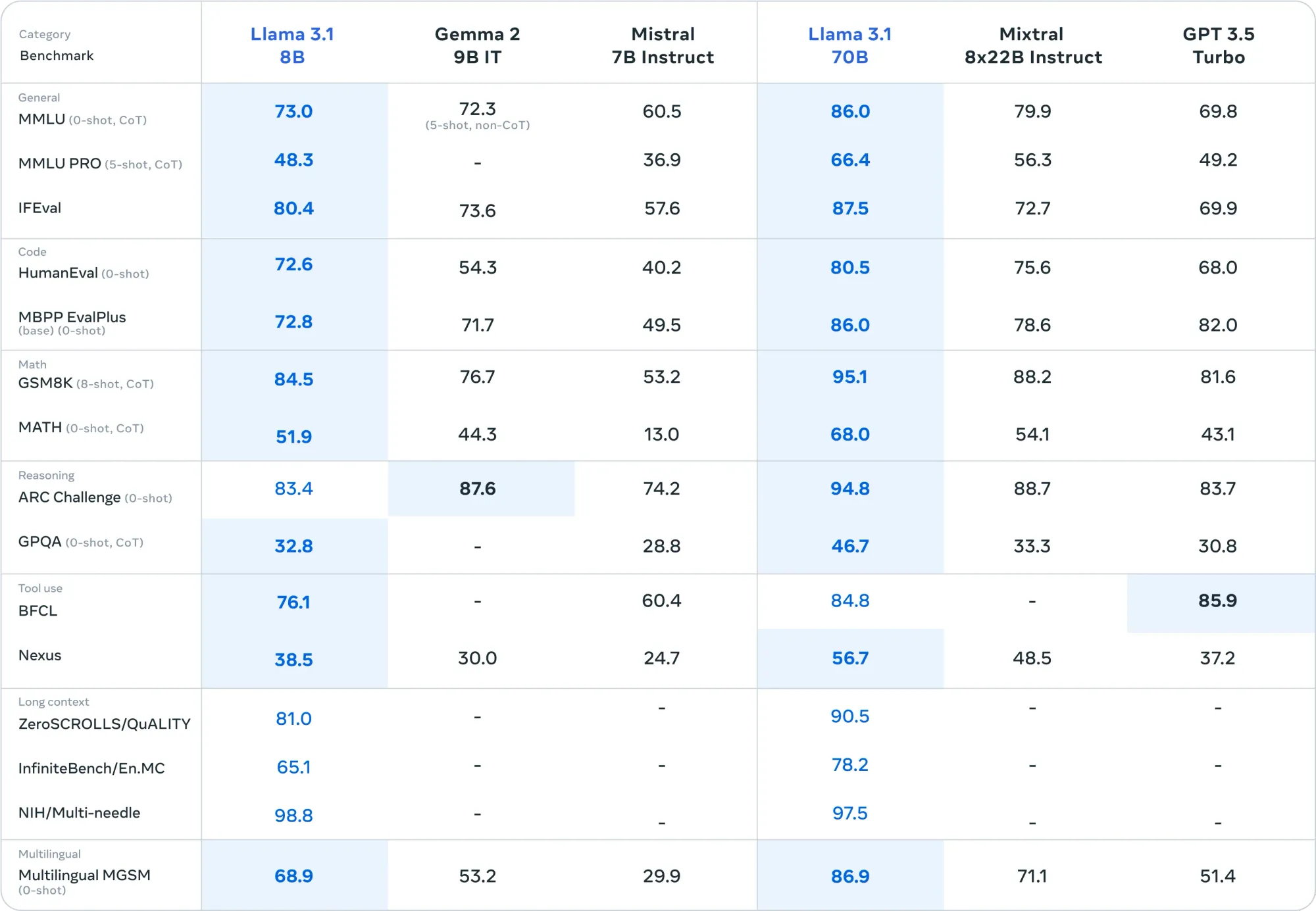
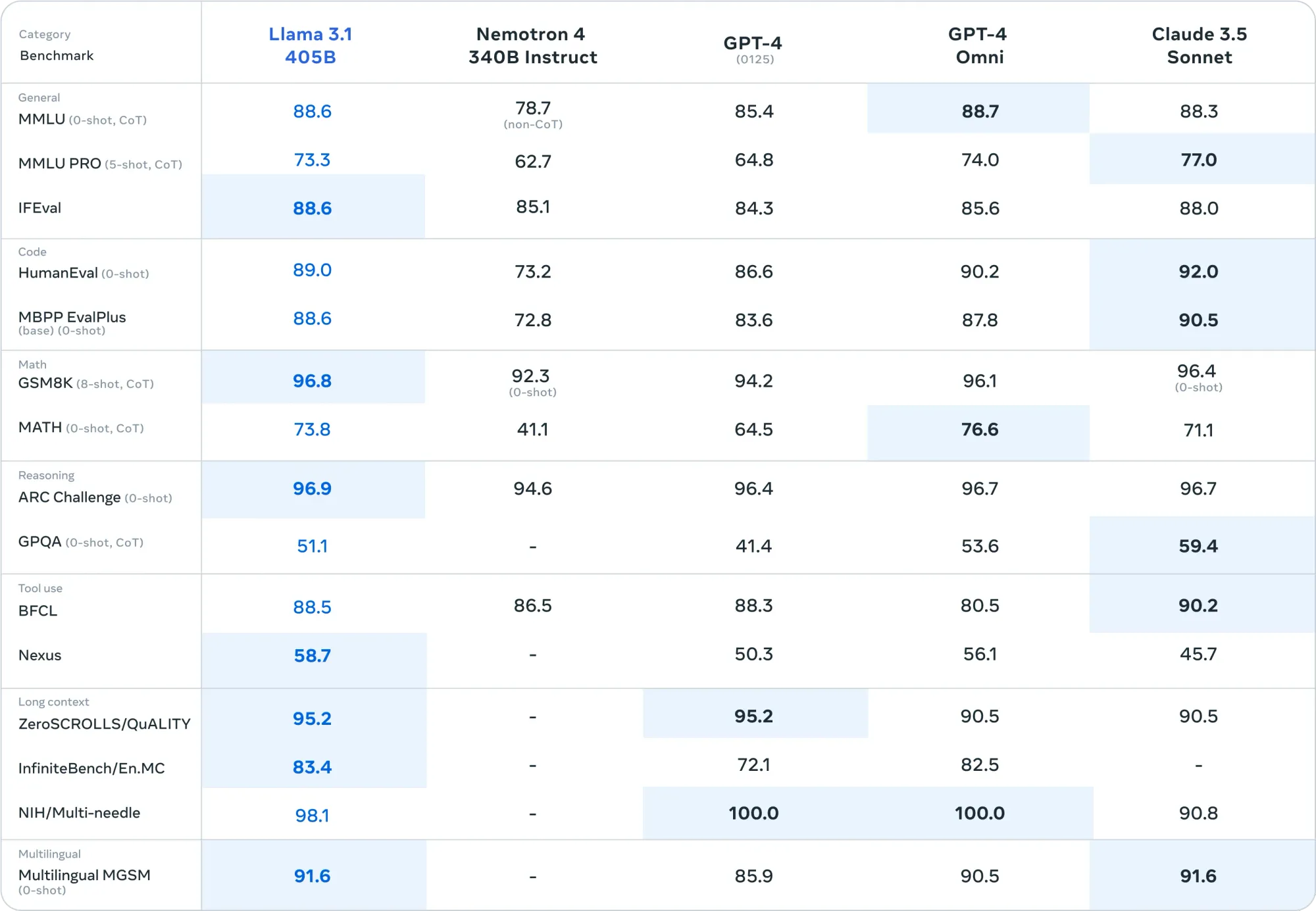
Llama 3.1 Benchmark. Image Source: https://ai.meta.com/blog/meta-llama-3-1/
What is Ollama?
Ollama is a tool that simplifies the deployment and management of large language models (LLMs) on local hardware. It allows you to run models like LLaMA 3.1 efficiently on your machine, leveraging your hardware resources.
Step 1: Install Ollama
curl -fsSL https://ollama.com/install.sh | sh
Step 2: Start the Ollama Server
ollama serve
Step 3: Download the LLaMA 3.1 Model
Ollama provides pre-trained models for various tasks. To download the LLaMA 3.1 model, use the following command:
ollama pull llama3.1
This command fetches the model and stores it locally on your machine.
Step 4: Run the LLaMA 3.1 Model
You can interact with the LLaMA 3.1 model via Ollama’s command-line interface (CLI) or through an API. Here’s how to use the CLI:
ollama run llama3.1
The model will process your query and return the response.
Conclusion
Installing and running the LLaMA 3.1 model locally with Ollama allows for greater control, enhanced privacy, and flexibility compared to cloud-based solutions. By following this guide, you can efficiently set up and manage your own LLM on your local hardware. Whether you’re developing applications, conducting research, or exploring AI, Ollama empowers you to harness the capabilities of large language models right on your machine.
Read Next

FreeBSD vs Linux in 2024: A Comprehensive Comparison
The world of operating systems is dynamic and constantly evolving. Two significant players in this realm are FreeBSD and Linux. Both have long histories and loyal followings, yet they cater

How to install certbot on FreeBSD
Certbot is a tool that automates the process of obtaining and renewing SSL/TLS certificates from Let’s Encrypt, a free Certificate Authority (CA). This guide will walk you through